Deep Learning Face Attributes in the Wild

Abstract
Predicting face attributes in the wild is challenging due to complex face variations. We propose a novel deep learning framework for attribute prediction in the wild. It cascades two CNNs, LNet and ANet, which are fine-tuned jointly with attribute tags, but pre-trained differently. LNet is pre-trained by massive general object categories for face localization, while ANet is pre-trained by massive face identities for attribute prediction. This framework not only outperforms the state-of-the-art with a large margin, but also reveals valuable facts on learning face representation. (1) It shows how the performances of face localization (LNet) and attribute prediction (ANet) can be improved by different pre-training strategies. (2) It reveals that although the filters of LNet are fine-tuned only with image-level attribute tags, their response maps over entire images have strong indication of face locations. This fact enables training LNet for face localization with only image-level annotations, but without face bounding boxes or landmarks, which are required by all attribute recognition works. (3) It also demonstrates that the high-level hidden neurons of ANet automatically discover semantic concepts after pre-training with massive face identities, and such concepts are significantly enriched after fine-tuning with attribute tags. Each attribute can be well explained with a sparse linear combination of these concepts.
Spotlight
Materials


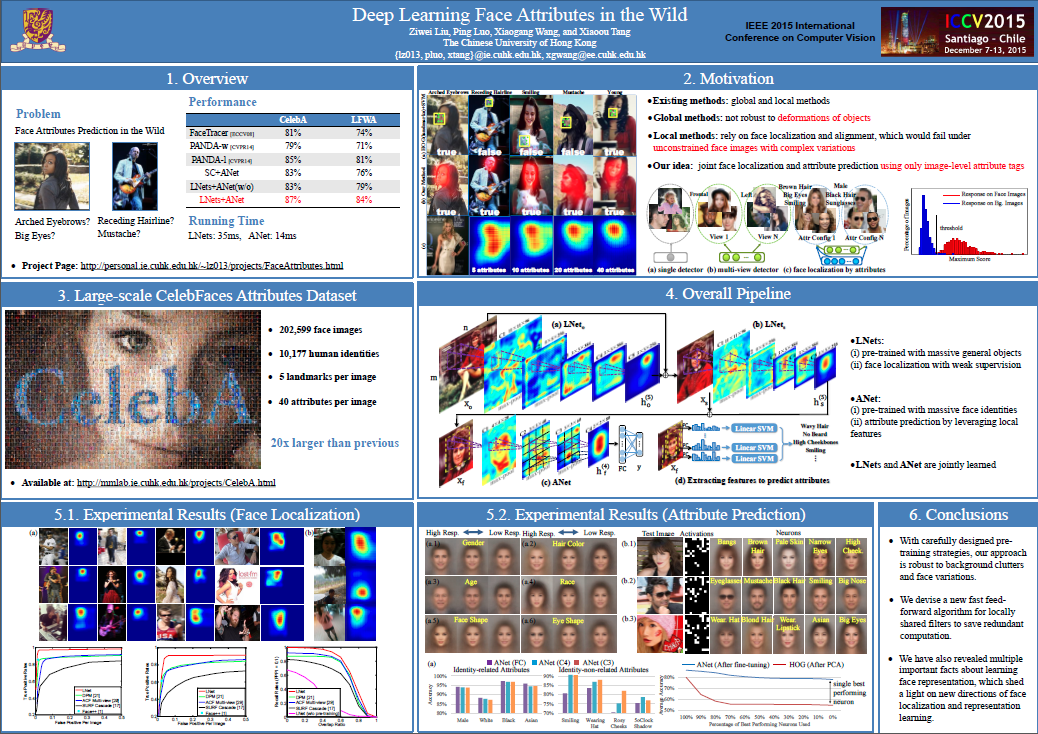
Dataset
CelebFaces Attributes Dataset (CelebA) is a large-scale face attributes dataset with more than 200K celebrity images, each with 40 attribute annotations. The images in this dataset cover large pose variations and background clutter. CelebA has large diversities, large quantities, and rich annotations, including
10,177 number of identities,
202,599 number of face images, and
5 landmark locations, 40 binary attributes annotations per image.

CelebA Dataset
Related Dataset
Citation
@inproceedings{liu2015faceattributes,
author = {Liu, Ziwei and Luo, Ping and Wang, Xiaogang and Tang, Xiaoou},
title = {Deep Learning Face Attributes in the Wild},
booktitle = {Proceedings of International Conference on Computer Vision (ICCV)},
month = December,
year = {2015}
}