Talking Face Generation by Adversarially Disentangled Audio-Visual Representation
Abstract
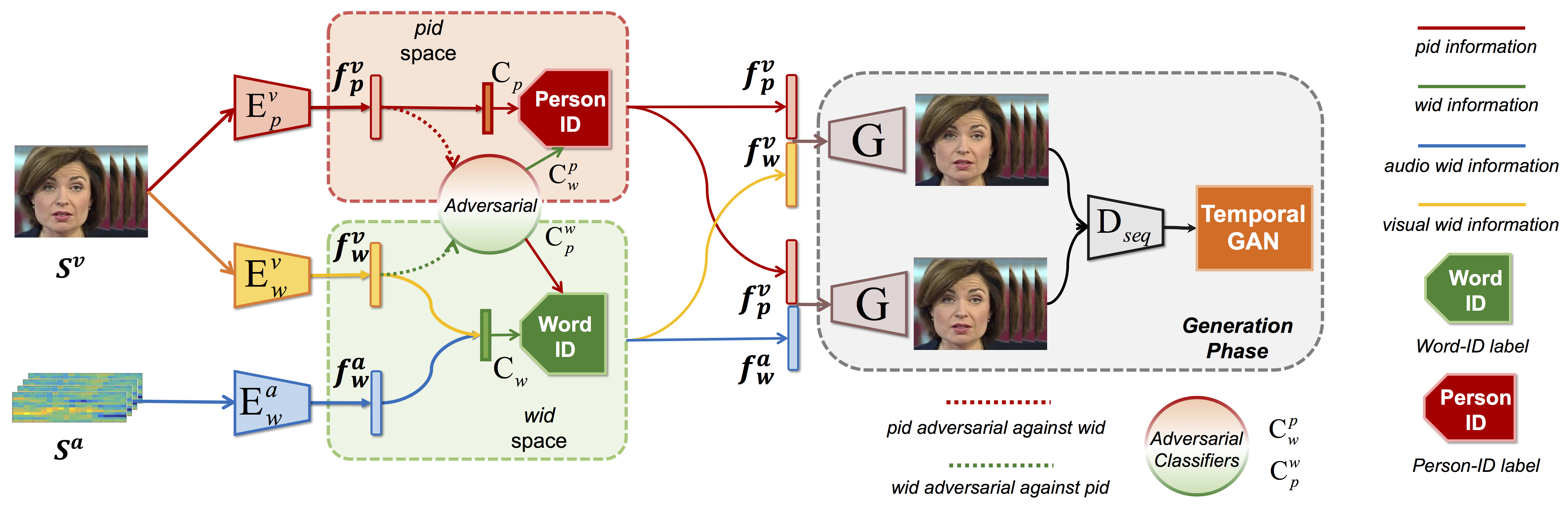
Talking face generation aims to synthesize a sequence of face images that correspond to given speech semantics. However, when people talk, the subtle movements of their face region are usually a complex combination of the intrinsic face appearance of the subject and also the extrinsic speech to be delivered. Existing works either focus on the former, which constructs the specific face appearance model on a single subject; or the latter, which models the identity-agnostic transformation between lip motion and speech. In this work, we integrate both aspects and enable arbitrary-subject talking face generation by learning disentangled audio-visual representation. We assume the talking face sequence is actually a composition of both subject-related information and speech-related information. These two spaces are then explicitly disentangled through a novel associative-and-adversarial training process. The disentangled representation has an additional advantage that both audio and video can serve as the source of speech information for generation. Extensive experiments show that our proposed approach can generate realistic talking face sequences on arbitrary subjects with much clearer lip motion patterns. We also demonstrate the learned audio-visual representation is extremely useful for applications like automatic lip reading and audio-video retrieval.
Demo Video
Materials

Code and Models

Citation
@inproceedings{zhou2018talking,
title={Talking Face Generation by Adversarially Disentangled Audio-Visual Representation},
author={Zhou, Hang and Liu, Yu and Liu, Ziwei and Luo, Ping and Wang, Xiaogang},
booktitle={AAAI Conference on Artificial Intelligence (AAAI)},
year={2019}
}